Changing the hierarchy
What is different in v0.2.0-m6 - and why it matters
QuPath’s object hierarchy has been an important part of the software since the start.
It’s where all the annotations, cells and other objects reside - arranged in a hierarchical way according to a few (ostensibly) simple rules. It has served the software well… mostly.
In v0.2.0 the behavior is changing. The purpose of this post is to summarize how, and expand on my recent tweeting about the subject. If you use QuPath, it’s probably important to know this.
Hmmm, so in a moment of wild abandon I deleted a couple of dozen lines of code to see if #QuPath would survive. Now suddenly images with large & complex annotations work *much* more smoothly... pic.twitter.com/13rLlsywtc
— Pete Bankhead (@petebankhead) November 13, 2019
Goals of the object hierarchy
When I first wrote the object hierarchy, I had two main intentions:
- To be able to create a hierarchical representation of tissue structures
- To be able to dynamically calculate measurements quickly (e.g. number of cells in a region)
Through QuPath you could see the relationships between objects under the ‘Hierarchy’ tab:
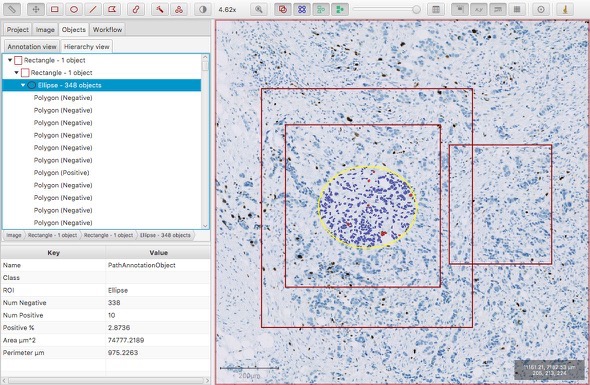
Conceptually, you might have something like this:
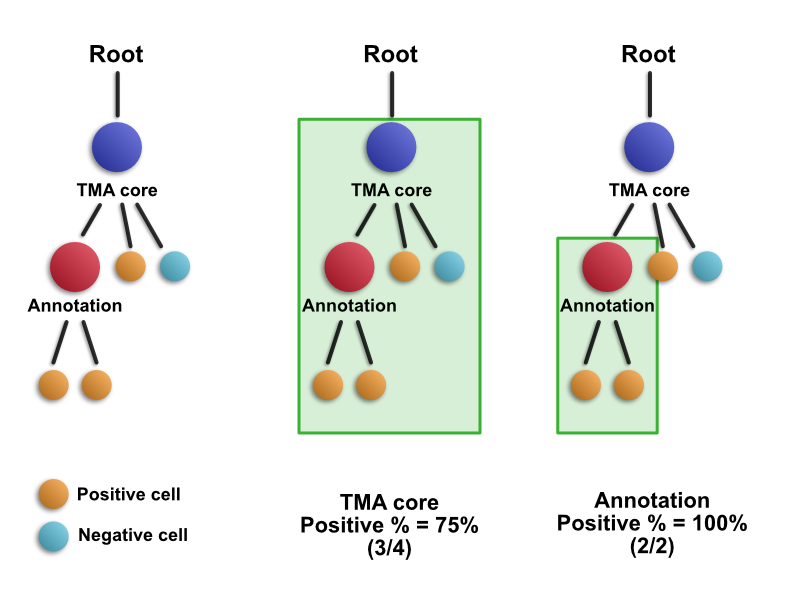
Measurements were made quickly by recursively ‘looking down the hierarchy’ to see what was there.
The goal was that it should feel intuitive… so you could use the software and it would do as you expect, without requiring you to think about it all the time.
In practice, it needed some defined rules that were sufficiently easy to understand and fast to apply. These rules were based on the Region of Interest (ROI) and object type, and the two main ones were:
- A detection (e.g. a cell) was a child of an object if its centroid was inside that object’s ROI
- An annotation was a child of an object if its entire ROI was inside that object’s ROI
There were a few subtleties (e.g. detections couldn’t parent annotations)… but that was basically it.
Problems with the object hierarchy
Those rules initially worked fine for my purposes: mostly tissue microarray analysis, sometimes analysis of larger tissue sections.
However as QuPath has become used more widely (> 60,000 downloads now…), more sophisticated commands were added (e.g. the pixel classifier), and the software was applied to more complicated applications, the limitations have become increasingly clear.
1. Performance
Firstly, automatically resolving the hierarchy can make things sloooow.
Detections aren’t really the problem: figuring out if a centroid is inside a ROI is fast. Doing this for a million cells may not be super-fast… but it is usually tolerable.
However figuring out if an annotation is fully inside another annotation can get very involved. Particularly as annotations become larger, more complex, and more numerous.
And now with the pixel classifier, it’s a lot easier to generate thousands of complex annotations.
QuPath’s performance with many annotations is a reoccurring topic on the forum, e.g. here and here.
To find the culprit when things are sloooow, VisualVM is fantastically helpful.
2. Ambiguity
If performance was the only problem, someone smarter than me might find a way to make it faster.
But that doesn’t solve a bigger issue: whenever objects overlap, the simple rules for resolving the hierarchy break down. It’s no longer clear what relationships objects should have with one another, and the results can be surprising.
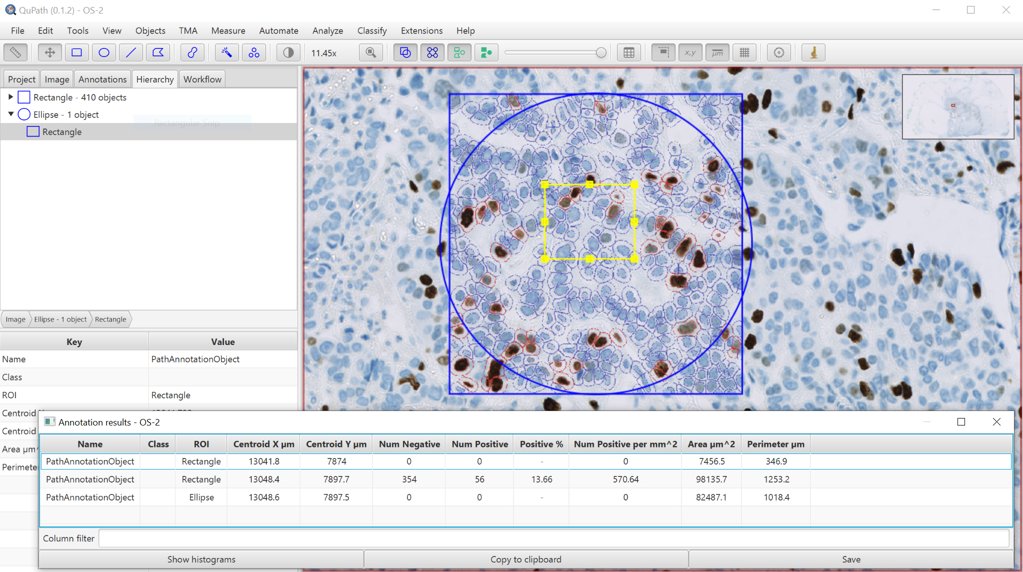
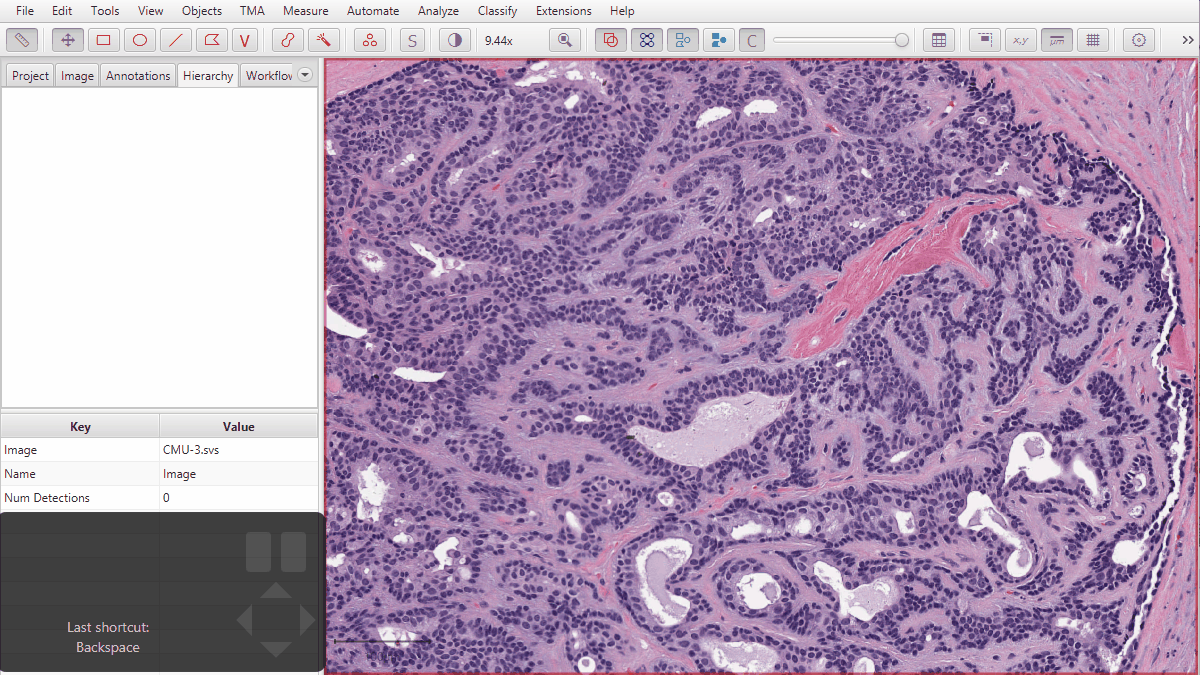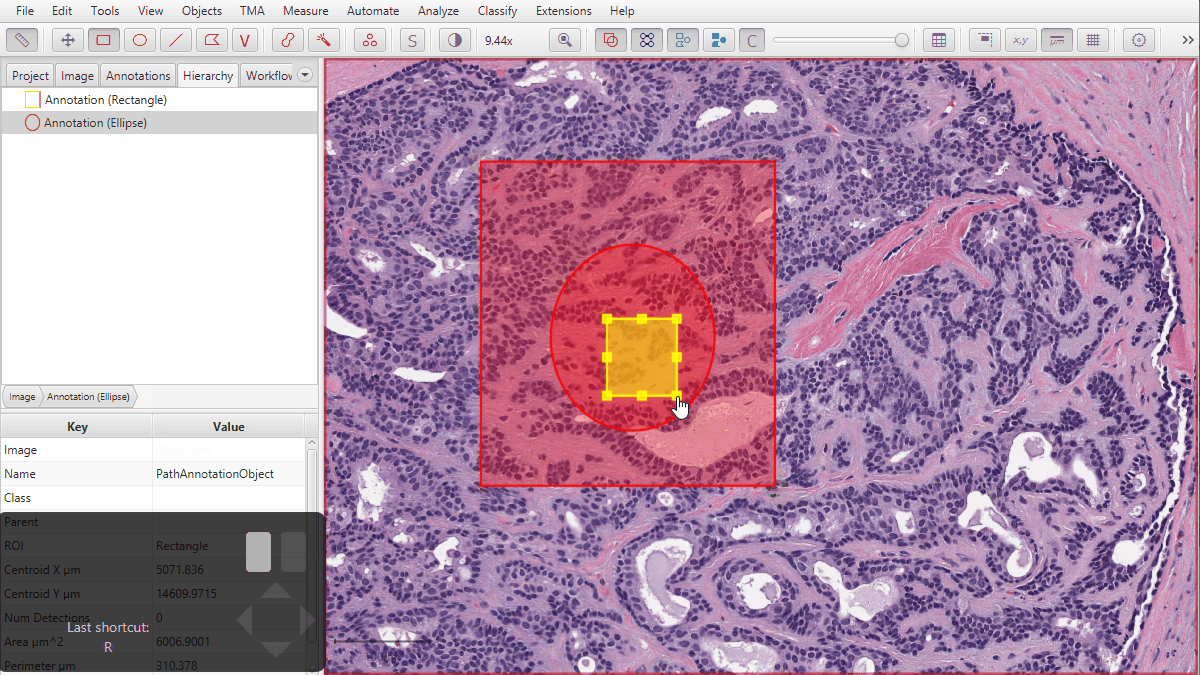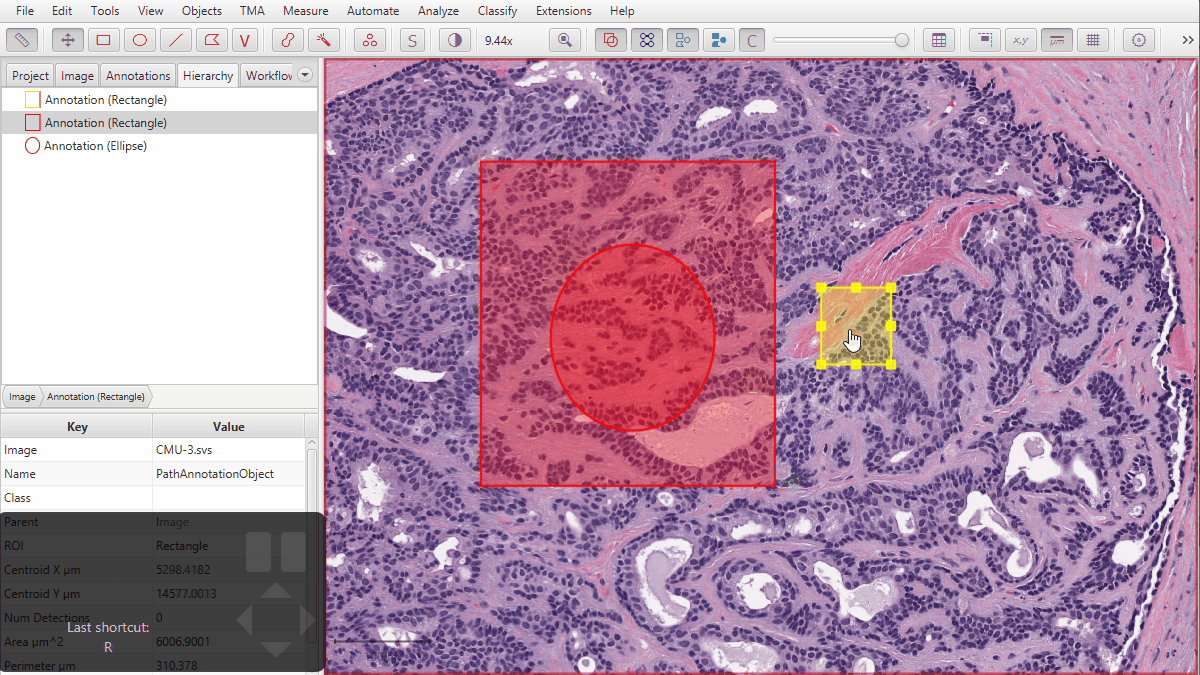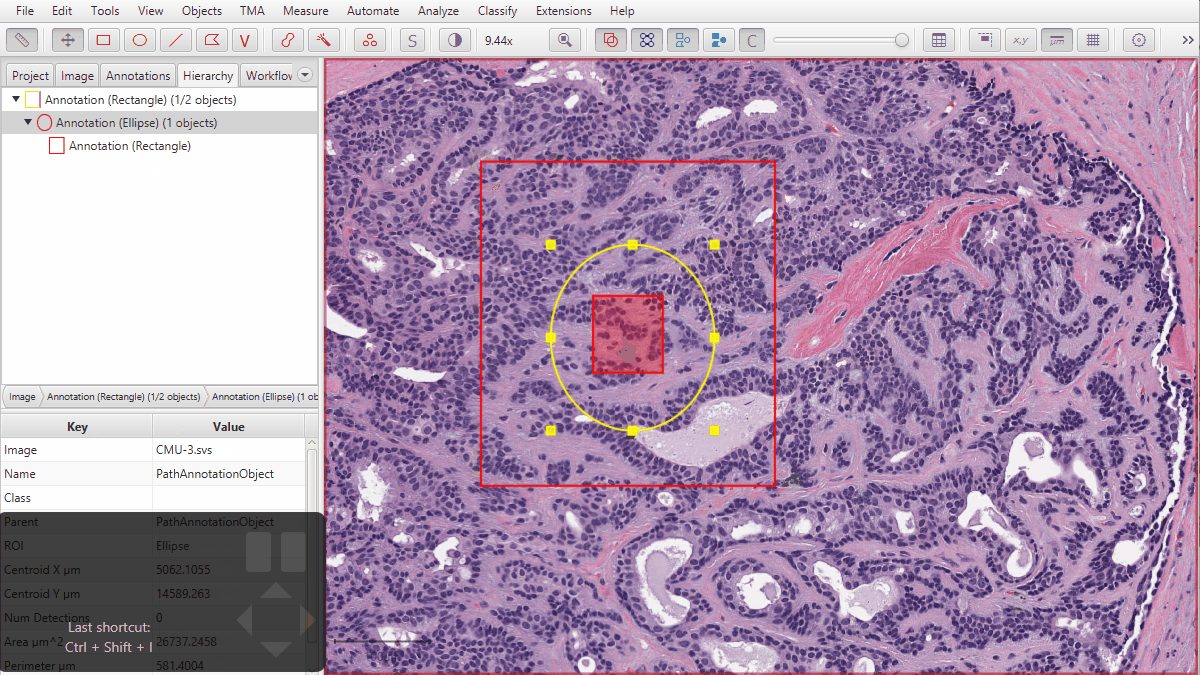
In the image below, which ellipse is the ‘parent’ of the cells in the middle?
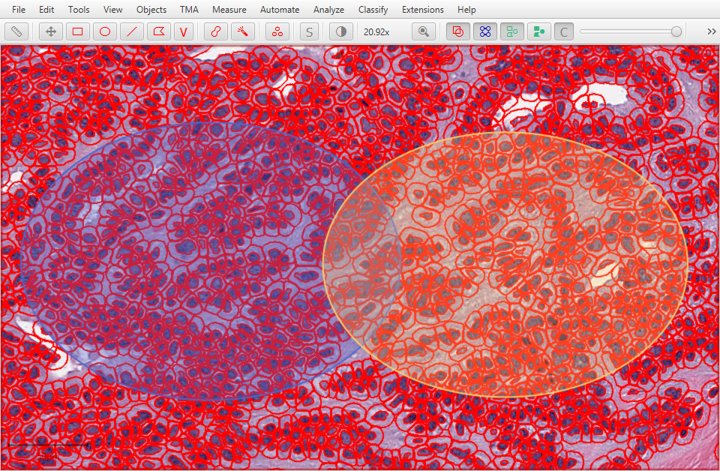
3. Confusion
In practice, the ambiguity wasn’t usually a problem. Very often, when using QuPath the hierarchy is basically ignored. Objects are requested like they all exist in a big list, and how they are represented internally doesn’t really matter.
But sometimes it could cause confusion.
For example, in the image below from v0.1.2, one would expect that the selected rectangle contains cells. But because it is a ‘child’ of the ellipse, and the ellipse is not completely contained within the outer rectangle, it doesn’t - at least as far as the hierarchy is concerned.
Changes in v0.2.0-m1
My first attempt to address this was to make the hierarchy less important.
This was achieved by always counting detections inside annotations based on their spatial location, not where they happened to fall in the hierarchy.
The change was introduced in v0.2.0-m1 and depended on Java Topology Suite (JTS). Applying it to the example above, we get a result that I think is considerably more intuitive.
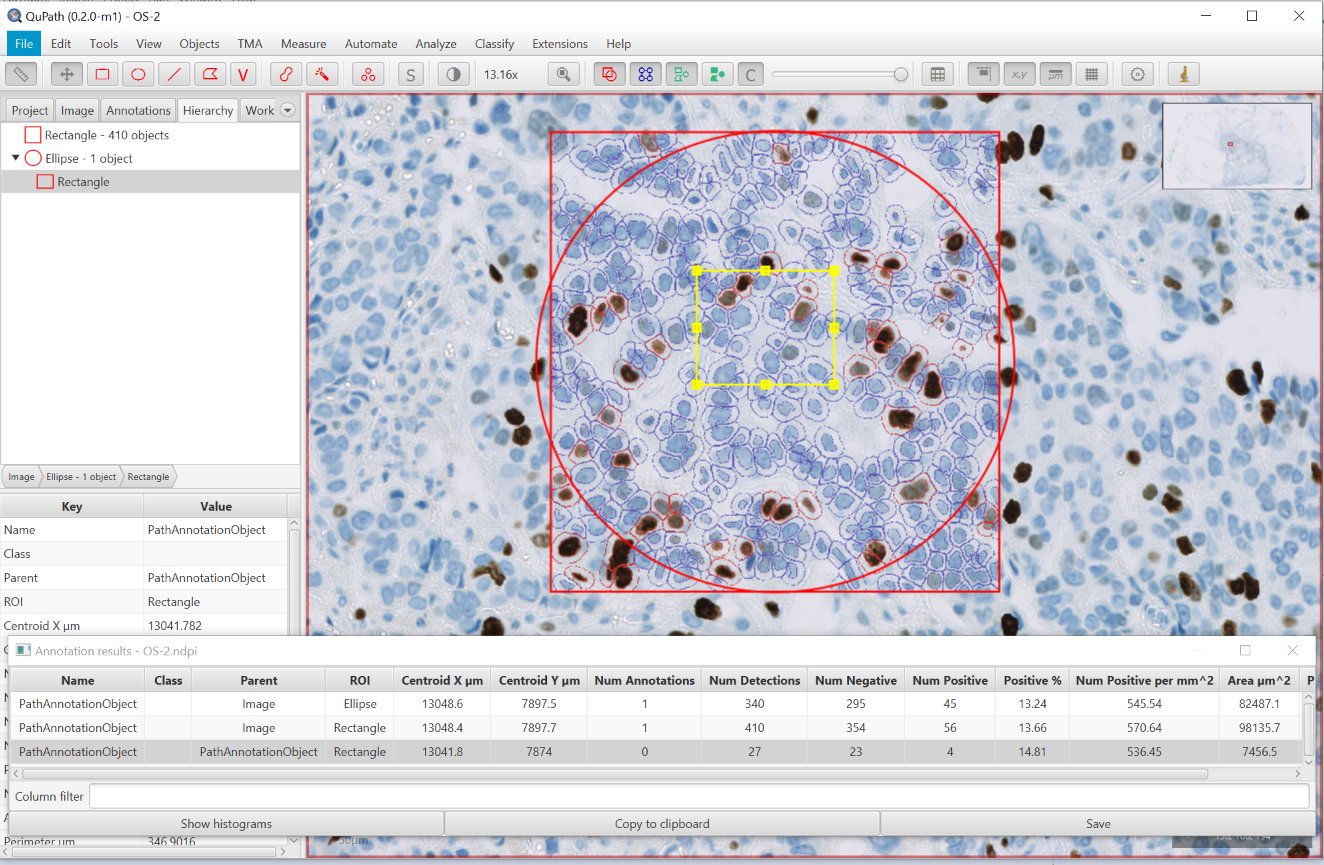
JTS brings all manner of very useful operations that can be performed on ROIs - and here the key feature is a spatial cache that makes it much faster to find objects based on location. This has made the performance aspect of using a hierarchy less critical.
Putting this into practice has involved being able to convert QuPath ROIs to a corresponding JTS representation (a ‘Geometry’). This has proven deceptively difficult, but after some teething problems in m6 I think this now works robustly. If you find ROIs that fail, please let me know…
This change helped reduce (not eliminate) the confusion of the hierarchy, but didn’t help performance.
In fact, performance is probably worse, because finding cells to count using the spatial cache is still slower than simply looking down the hierarchy.
Best of both worlds?
You might ask: if the hierarchy is so troublesome, why keep it at all?
Well, I still think the first of my original intentions makes sense: sometimes it is really helpful to be able to represent hierarchical structures within an image. Having a flat list of objects (e.g. like ImageJ’s ROI Manager) can be very limiting. So it would be nice not to dispense with it entirely.
The proposed solution in v0.2.0-m6 is to give the user control.
The idea is this:
- Keep QuPath’s hierarchy the same internally. Objects do still have parent/child relationships, and are stored in a hierarchical way.
- When adding detections, continue to add them as children of the annotation/TMA core that was selected whenever they were first detected. This hasn’t changed.
- When adding an annotation, make the default behavior to add it directly below the image: don’t try to resolve where it should fit in based on the old (and broken) rules about ‘completely contained’.
- Make it optional to request that the object is inserted to the ‘right’ place in the hierarchy.
The last point is achieved by a new Insert in hierarchy command, which you can access in three ways:
- Objects → Annotations… → Insert into hierarchy
- Right-clicking with one or more annotations selected
Ctrl + Shift + I
The rule for insertion is almost the same as before but takes into consideration the area of the annotations that might be parents. In short, the annotation will be assigned to the smallest potential parent that completely contains its ROI.
Here, you can see it in action. Notice that by default, annotations are in a ‘flat’ list - but the old hierarchical arrangement can be achieved individually or all together either with the menu options or using shortcut keys.
You can also use Objects → Annotations… → Resolve hierarchy to try to resolve all objects in the image in this way.
This is scriptable with resolveHierarchy(), but best avoid using it if you have a lot of objects.
Together, I hope these changes will retain the advantages of representing objects hierarchically without the previous problems, and thereby make it possible to use QuPath for increasingly complex tasks.
Outlook
I don’t know if the approach in v0.2.0-m6 is the best one, although it’s the best I’ve come up with so far.
I suspect refinements will be needed as people try it out and find limitations.
But I hope that by including it in a milestone version that can be easily tested, and explaining the reasons here, it can start a discussion that helps iron out any bugs - or identifies a better approach altogether.
Please let me know what you think!